天津工业大学的研究人员最近开发了一种新的基于大脑网络的框架,用于识别聋人的情绪。该框架发表在IEEE Sensors Journal 上的一篇论文中,专门基于一种称为堆叠集成学习的计算技术,该技术结合了多种不同机器学习算法的预测。
“在与聋哑学生的日常交流中,我们发现他们识别其他人的情绪主要是基于视觉观察,”进行这项研究的研究人员之一于松告诉Tech Xplore。“与正常人相比,聋人对情绪的感知也存在一定差异,这可能会导致日常生活中出现心理偏差等问题。”
过去大多数旨在开发情绪识别模型的研究都是在没有感觉障碍的个体上进行的。宋和他的同事着手填补文献中的这一空白,开发了一个框架,可以专门对聋人的情绪进行分类。
首先,研究人员检查了在三种不同情绪状态(积极、中性和消极)下,没有听力障碍的受试者和聋人之间大脑活动和功能连接的差异。为此,他们在天津工业大学招募了 15 名聋哑学生,并收集了与 SEED 数据集相似的大脑记录,SEED 数据集是一个著名的数据集,包含几个没有听力障碍的受试者的脑电图信号。
“通常情况下,脑电图特征是从时域、频域和时频域中提取的,用于情感识别,”宋解释说。“这是因为神经科学理论表明,认知过程是通过大脑中信息的传播和不同大脑区域之间的相互作用来反映的。因此,我们决定开发一种新的大脑网络堆叠集成学习模型,用于情感识别,该模型结合了不同大脑区域收集的信息。算法。”
在他们最初的实验中,宋和他的同事发现阈值的选择在他们构建大脑网络中发挥了重要作用。为了减少错误连接并保留有效连接,他们因此建议在锁相值 (PLV) 连接矩阵中使用双到二进制的阈值。PLV 是两个不同时间序列之间相位同步的度量,广泛用于通过分析成像数据(例如 MEG 和 EEG 扫描)来检查大脑连接。
“然后我们从大脑网络中提取全局特征和局部特征,并使用我们开发的堆叠集成学习框架对提取的特征进行分类,”宋说。“我们的实验结果表明,所提出的模型可以学习区分性和领域鲁棒性 EEG 特征,以提高情绪识别的准确性。与深度学习不同,我们的模型也适用于小样本数据,可以有效降低过拟合的风险。”
在他们的实验中,Song 和他的同事发现,他们的模型可以识别聋人的情绪,比识别没有听力障碍的人的情绪要准确得多。对此的一种可能解释是,由于缺乏与情绪获取相关的渠道,聋人对情绪的理解更简单。
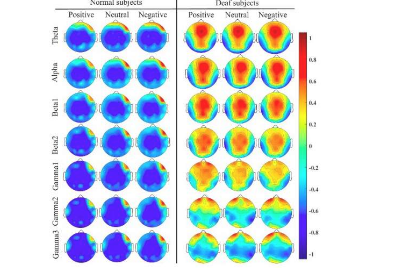
值得注意的是,研究人员的模型明显优于其他最先进的情绪识别模型。此外,研究小组发现,在充满情绪的状态下,聋人和非听力障碍受试者之间大脑活动和功能连接的差异比在中性条件下更明显。
“对于正常受试者,我们通过调查大脑活动发现左前额叶和颞叶可能是最丰富的情绪信息区域,”宋说。“对于聋人来说,额叶、颞叶和枕叶可能是最丰富的情绪识别信息区域。”
该研究提供了有关不同情绪状态下聋人和听力人的大脑活动之间差异的宝贵见解。例如,宋和他的同事观察到,与听力受试者相比,聋哑受试者的枕叶和顶叶表现出更高的激活,而颞叶的激活则更低。这些差异可能与聋人参与者在实验过程中观看向他们展示的情绪电影剪辑时大脑中的补偿机制有关。
“我们发现,对于正常受试者,额叶之间的局部通道间关系可能为情绪识别提供有用的信息,额叶、顶叶和枕叶之间的全局通道间关系也可能提供有用的信息,”宋说。“另一方面,对于聋人来说,额叶、颞叶和枕叶之间的全局通道间关系对于情绪识别具有重要意义,大脑左右半球之间的通道间关系也可能提供有用的信息。”
这项研究可能有几个重要的意义。首先,这项工作可以提高目前对聋人大脑中情绪状态如何表现的理解,以及这与没有听力障碍的人的情绪处理有何不同。
此外,他们开发的情绪识别模型可用于识别聋人在日常生活和临床环境中的情绪。此外,研究人员的工作可以为制定减少聋人和听力人之间情绪认知差异的策略提供信息。
当应用于他们招募的 15 名聋人参与者时,该模型目前可以在受试者中实现大约 60% 的准确率。未来,Song 和他的同事希望提高他们模型的性能及其在不同个体之间很好地泛化的能力。
“最近,我们也开始招募更多的聋人受试者参与脑电情绪识别实验,情绪类别包括娱乐、鼓励、平静、悲伤、愤怒和恐惧,”宋补充说。“我们将继续扩大我们的数据集,并免费提供给其全球研究人员在以后的工作中,使他们可以研究大脑在不同情绪状态聋科目的神经机制。”