富士通实验室有限公司开发了AI技术,该技术可准确捕获基本特征,包括高维数据的分布和概率,以提高AI检测和判断的准确性。
包括通信网络访问数据,医学数据类型和图像在内的高维数据由于其复杂性而仍然难以处理,这使得获取目标数据的特征成为一个挑战。到现在为止,这有必要使用通过深度学习来减小输入数据的尺寸的技术,有时会导致AI做出错误的判断。
富士通将深度学习技术与其在图像压缩技术方面的专业知识相结合,并积累了多年的经验,以开发一种AI技术,从而可以利用深度学习技术优化高维数据的处理并准确地提取数据特征。它将图像压缩中使用的信息理论与深度学习相结合,优化了高维数据中要减少的维数以及通过深度学习进行降维后的数据分布。
富士通实验室副研究员中川彰(Akira Nakagawa)评论说:“这是应对AI领域近年来的主要挑战之一的重要一步:捕获数据的概率和分布。我们相信,这项技术将对性能有所贡献。 AI方面的改进,我们很高兴能够应用这些知识来改进各种AI技术。”
该技术的详细信息将在7月12日星期日的国际机器学习大会“ ICML 2020(2020年国际机器学习大会)”上进行介绍。
发展背景
近年来,各个业务领域对AI驱动的大数据分析的需求激增。人工智能也有望帮助支持检测数据异常,以揭示未经授权的网络访问企图,或甲状腺或心律失常数据的医学数据异常。
挑战性
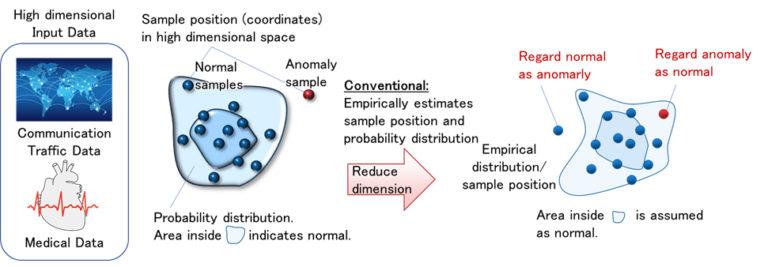
许多业务操作中使用的数据是高维数据。随着数据维数的增加,准确表征数据所需的计算复杂度呈指数增长,这种现象被广泛称为“维数诅咒” (1)。近年来,使用深度学习来缩小输入数据的尺寸的方法已被认为是有助于避免这一问题的有前途的候选方法。但是,由于在不考虑数据分布和缩减后出现概率的情况下减少了维数,因此无法准确地捕获数据的特征,并且AI的识别精度受到限制,并且可能会产生错误判断(图1) 。解决这些问题并准确获取高维数据的分布和概率仍然是AI领域中的重要问题。
关于最新技术
富士通开发了世界上第一个AI技术,该技术可以准确地捕获高维数据的特征而无需标记训练数据。
富士通针对检测不同领域数据异常的基准测试了这项新技术,包括由国际数据挖掘协会“知识发现和数据挖掘(KDD)”分发的通信访问数据,由美国大学分发的甲状腺数值数据和心律失常数据。加州尔湾。新开发的技术成功地在所有数据上实现了世界上最高的准确性,比传统的基于深度学习的错误率提高了37%。由于这项技术解决了AI领域的一项基本挑战,即如何准确捕获数据特征,因此有望证明其在解锁各种新应用程序方面的重要发展。
所开发技术的技术特征如下。
1.准确捕捉数据特征的理论证明
在图像和音频数据的压缩中,它们都是由几千到几百万个维组成的高维数据,通过多年的研究已经弄清了数据的分布和出现概率,以及通过以下方法减少维数的方法 已经建立了离散余弦变换(2)的方法以及针对这些已知分布和概率优化的其他方法。理论上已经证明,通过使用降维后的数据分布和概率来恢复数据,当原始图像/声音和恢复的图像/声音之间的劣化被抑制到恒定水平时,可以使压缩数据信息的量最小化。发生。
受图像压缩理论的启发,富士通在世界范围内首次证明了一种新的数学理论,即对于分布和概率未知的高维数据,例如通信网络访问数据和医疗数据,数据的维数降低了。通过作为神经网络的自动编码器(3),当恢复数据时,原始高维数据和恢复的数据之间的降级保持恒定值,而降维后的信息量最小化尺寸,可以准确地捕获原始高维数据的特征,并将维数降至最低。
2.使用深度学习的降维技术
通常,深度学习可以通过定义需要最小化的目标成本来确定即使在复杂问题中也可以最小化目标成本的参数组合。利用此功能,富士通引入了参数来控制自动编码器(该编码器可减小数据的维数)和降维后的数据分布。我们的方法将压缩后的信息量作为目标成本进行计算,并通过深度学习对其进行优化。当根据上述1中描述的数学理论进行优化时,这可以精确地表征尺寸减小的分布和数据的概率。
未来的计划
展望未来,富士通将推动新技术的实际应用,以期在2021财年末将其投入实际应用,并将其应用于更多的AI技术。
[1] 维数诅咒:描述随着数据维数增加而计算复杂度呈指数增长的现象。
[2] 离散余弦变换:一种傅立叶变换,可将图像或音频信号变换为频率分量的强度。
[3]自动编码器:一种基于神经网络的无监督尺寸压缩技术。